Facebook是一个社会化网络站点,它于2004年2月4日上线。每个用户在facebook上有自己的档案和个人页面,用户之间可以通过各种方式发生互动:留言、发站内信,评论日志。虽然目前在国内无法访问facebook,但其强悍的技术架构还是值得我们去研究分析和总结的,或许我们可以从中得到一点启发。
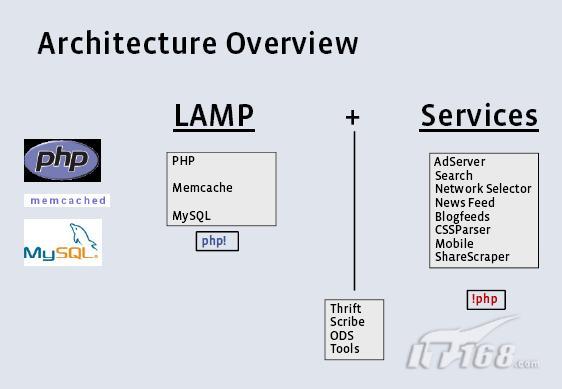
facebook的设计原则是模块化原则、整合化原则、清晰化原则,其架构设计的目标是简单、高效。facebook的架构是基于LAMP,差不多是用LAMP实现的最大的动态站点,以下是facebook架构图概览:
为什么 Facebook 选择 PHP 而不是其他语言? 用Flickr 的 这句话就能说明了: "Languages's don't Scale, Architecture Scale"。详见
MySql经验:
主要用于做Key-Value类型的存储操作,数据随机分布在多台逻辑实例上,访问多数基于全局ID。
逻辑实例分散在多台物理主机上(超过1800台),负载均衡在物理层进行。 不做读复制。尽量不做逻辑数据迁移(成本太高)。 不做JOIN操作(豆瓣在QCon上也阐述了这一点)。数据是随机分布的,关联操作反而带来了极大的复杂度。 对于数据访问,主要的操作集中在最新的数据上,针对这部分做优化,旧的数据进行归档。在中心DB绝不存储非静态数据。
使用服务或者Memcached进行全局查询。
Memcached经验:
一个比较有价值的是关于个人页面数据的获取的描述。这个就完全是需要做单页面Benchmark的细致活儿了,可能还需要产品经理能够理解工程师的"抵抗"。
获取个人信息数据:通过Cache,隐性通过用户所在的DB获取(基于User-ID获知DB)
获取朋友连接信息:通过Cache,否则的话通过DB(基于User-ID获知DB)
并行抓取每个朋友的10个照片相册ID,从Cache抓取,如果失效,再从DB抓取(基于相册ID)
并行抓取最近相册中的照片数据
运行PHP把整个业务逻辑跑出来
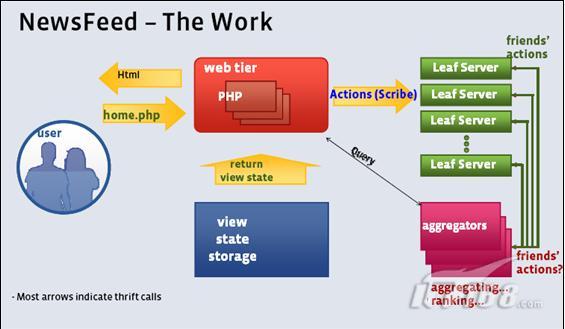
FacebookNewsFeed的架构示意图:

Facebook搜索功能的架构示意图